

2024年1月19日にリリースされたLoRA作成用拡張機能「 sd-webui-traintrain 」をご紹介します。
この sd-webui-traintrain (以下、TrainTrain)は、hako-mikanさんが開発した拡張機能で、外部の専用ツールなどを使わず、Stable Diffusion WebUI(AUTOMATIC1111)上でLoRA、iLECO、差分LoRAを作れる優れモノです。
実際に使ってみましたが、使い方は非常に簡単。
設定項目が最小限に精選されており、ほぼ標準設定のままでもLoRAを作ることができます。
本記事では、LoRAを作ったことがない方でも理解できるように、できるだけ分かりやすく解説したいと思います。
iLECOと差分LoRAについては、別記事で解説します。
Stable Diffusion WebUI(AUTOMATIC1111)のインストールについては、以下の記事で詳しく解説していますので、ぜひお読みください。

1.LoRAを作るために必要なもの
必要なものは、以下のとおりです。
- Stable Diffusion WebUI(AUTOMATIC1111)
- Dataset Tag Editor(拡張機能)
- TrainTrain(拡張機能)
- 学習させる画像
Stable Diffusion WebUI(AUTOMATIC1111)に2つの拡張機能をインストールする必要があります。拡張機能のインストールは、非常に簡単で時間もかかりません。
各拡張機能のインストールについては、後述の「4. sd-webui-traintrain のインストール」「5.stable-diffusion-webui-dataset-tag-editorのインストール」で解説します。
2.学習させる画像についての注意点
LoRA作成で一番重要なものは学習させる画像です。
ここで手を抜くと良いLoRAは作れません。
学習させる画像については、できるだけ綺麗な画像を最低10~20枚程度準備します。
画像の大きさは、512*512 または 1024*1024 を基本にします。
縦長や横長の画像が混在していても学習可能です。
画質が荒いと、その画質の荒さまで学習してしまうことがあるので注意が必要です。
ネットからダウンロードした写真やスマホのゲーム画面のスクショなどは学習画像に向きません。
高画質なものであれば問題ありませんが、大抵の場合、画質が荒いです。元々画質が荒い画像を無理に大きくすると余計に画質が荒れてしまいます。
Stable Diffusionで学習画像を生成する場合には、Hires.Fix(高解像度補助)などを施した方が良いと思います。
以前、実写系のLoRAを作成した際、Hires.Fixを施していない画像を使用したところ、瞳の形やまつ毛、肌の質感などにかなりの悪影響が出ました。
実写系の場合は、無加工の写真データやプリントした写真を高解像度スキャンして使用する方法が良いかもしれません。
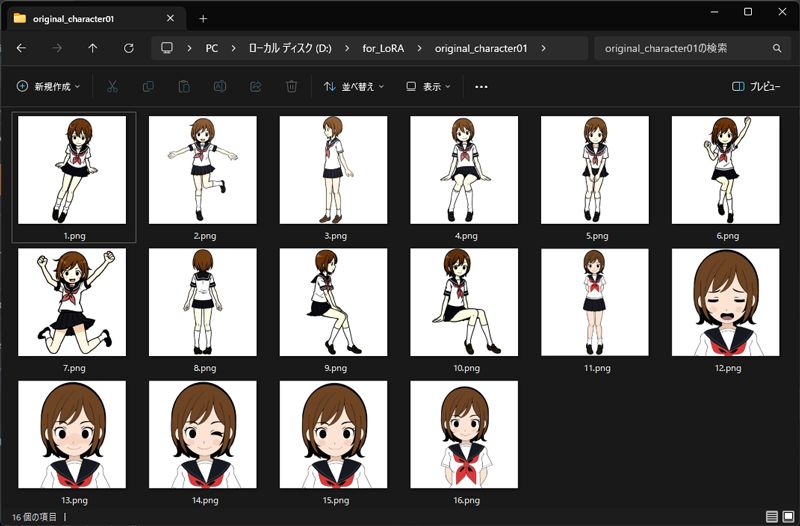
今回は、以下の16枚のイラスト画像(大きさは1024*1024)を使用してLoRAを作成します。

3.LoRAを作る流れ
LoRA作成の流れは、ザックリ以下の3つです。
- 学習させる画像を準備する(前述のように、多分これが一番大変)
- 画像からタグを抽出して整える(Dataset Tag Editorを使用)
- LoRAの作成(TrainTrainを使用)
4. sd-webui-traintrain のインストール
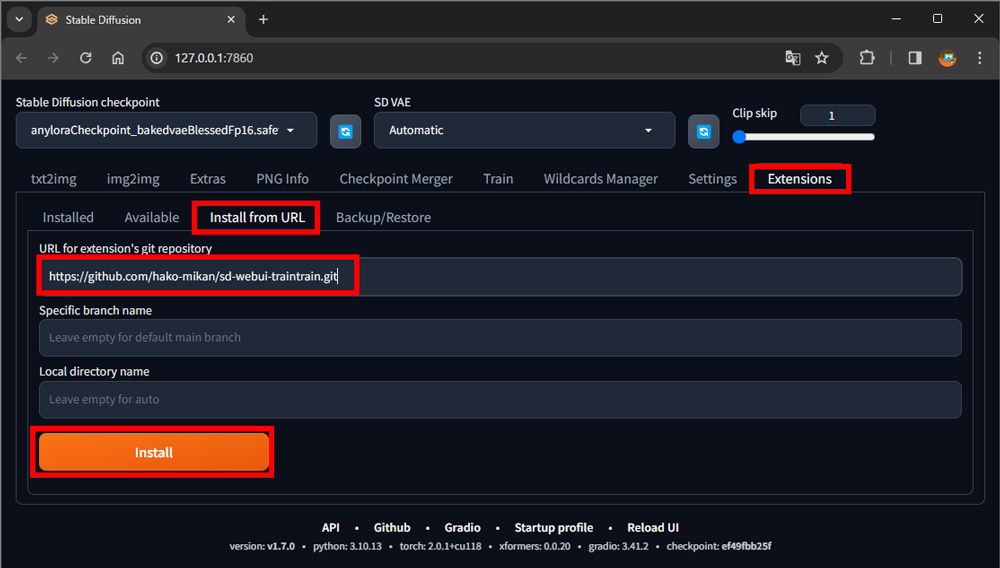
1.Extensionsタブを選択
2.Install from URLタブを選択
3.URL for extension’s git repository欄に以下のURLをペースト
https://github.com/hako-mikan/sd-webui-traintrain.git
4.Installボタンをクリック
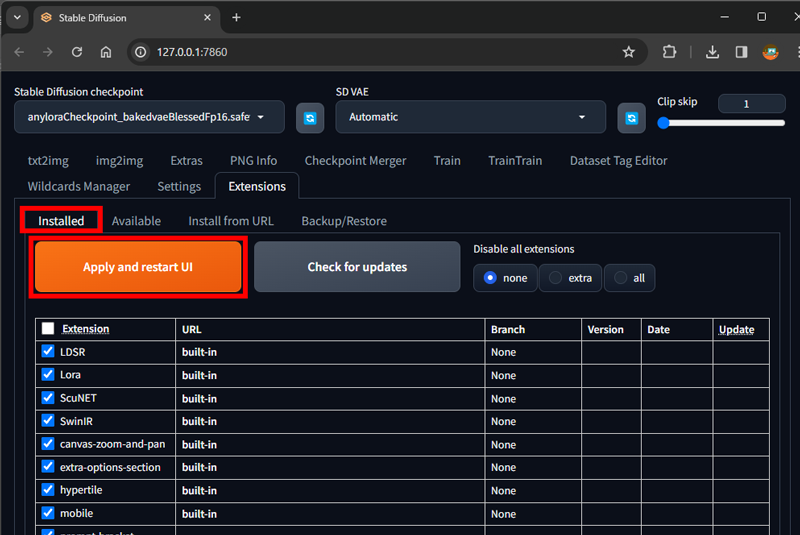
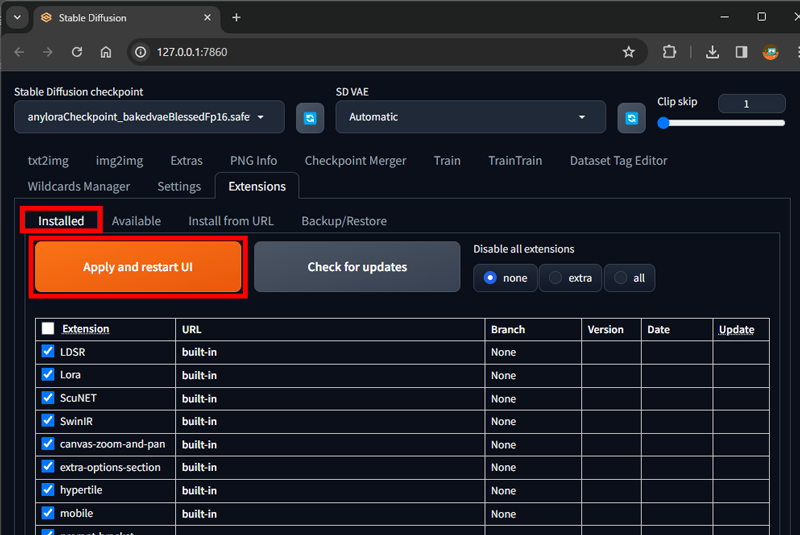
5.Installedタブを選択
6.Apply and restart UIボタンをクリック
5.stable-diffusion-webui-dataset-tag-editorのインストール
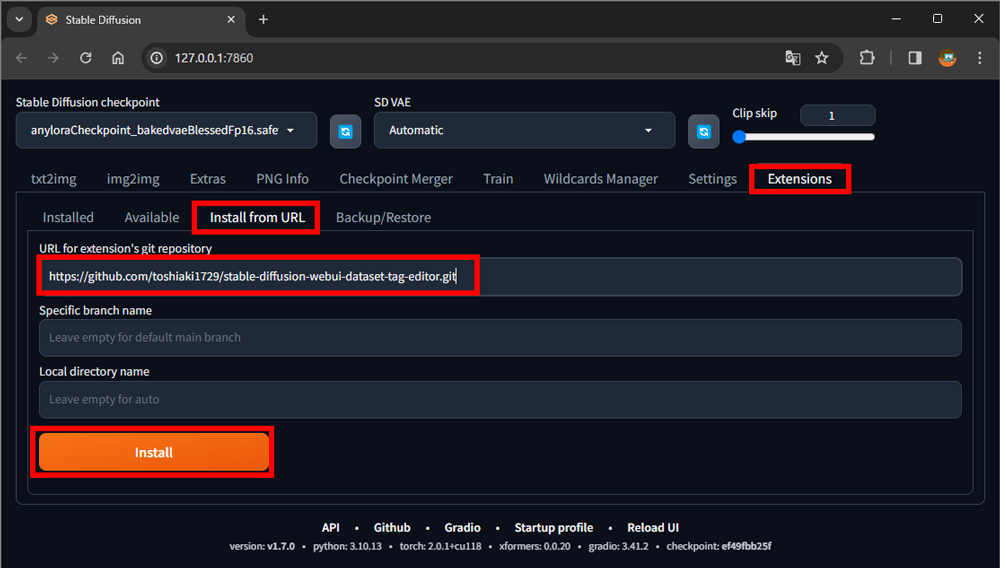
1.Extensionsタブを選択
2.Install from URLタブを選択
3.URL for extension’s git repository欄に以下のURLをペースト
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor.git
4.Installボタンをクリック
5.Installedタブを選択
6.Apply and restart UIボタンをクリック
6.画像からタグを抽出して整える(Dataset Tag Editorでの作業)
Dataset Tag Editorを使って、画像からタグを抽出し、「学習させたいタグを消去」します。
こうして整えたタグをテキストファイルとして書き出します。
タグの抽出、タグの消去、テキストファイル書き出しは、全てDataset Tag Editorで行います。
6-1.画像を任意のフォルダにまとめる
準備した画像を任意のフォルダにまとめておきます。この例では、以下のフォルダ内に画像をまとめてあります。
d:\training\original_character01
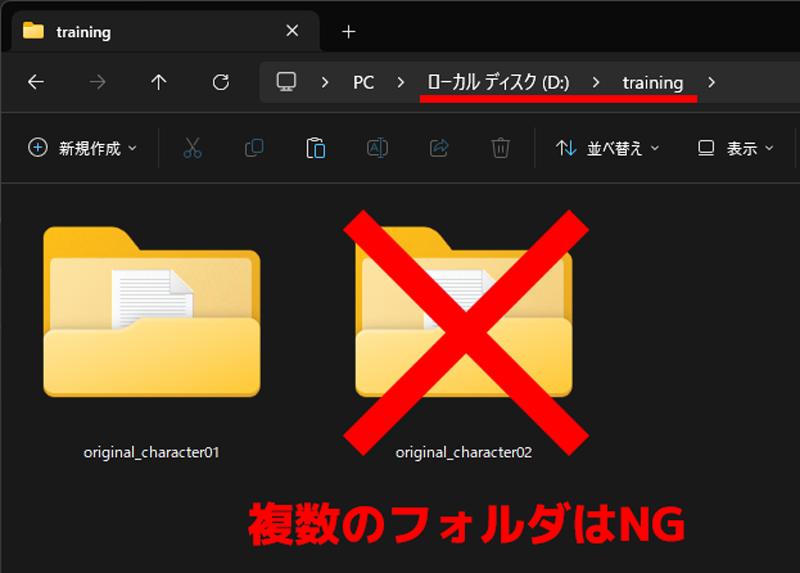
LoRAを作成する際、画像を保存したフォルダの一つ上の階層を指定する必要があるので、CドライブやDドライブなどの直下のフォルダではなく、training などの任意のフォルダを作成してから、その中にもう一つフォルダを作成して画像をまとめておきます。
また、フォルダを複数作成しないようにしてください。
6-2.画像からタグを抽出する
⓪.画像フォルダのアドレスをコピー
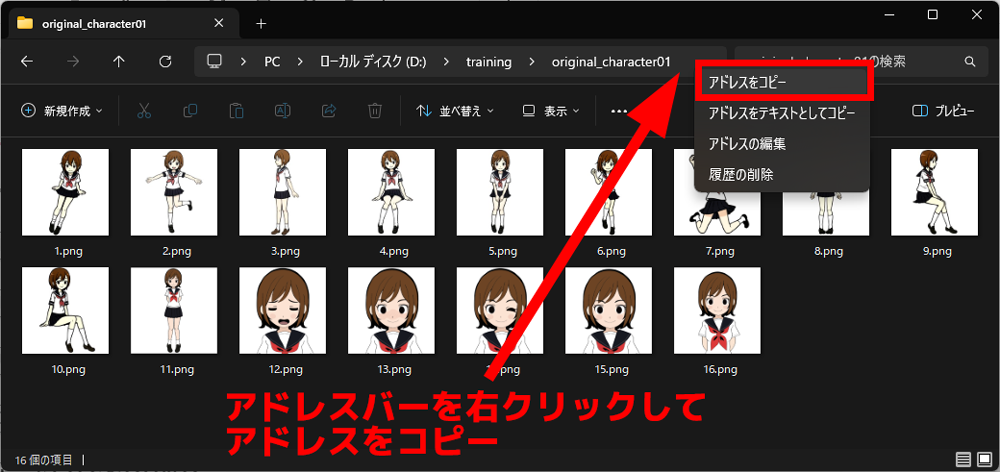
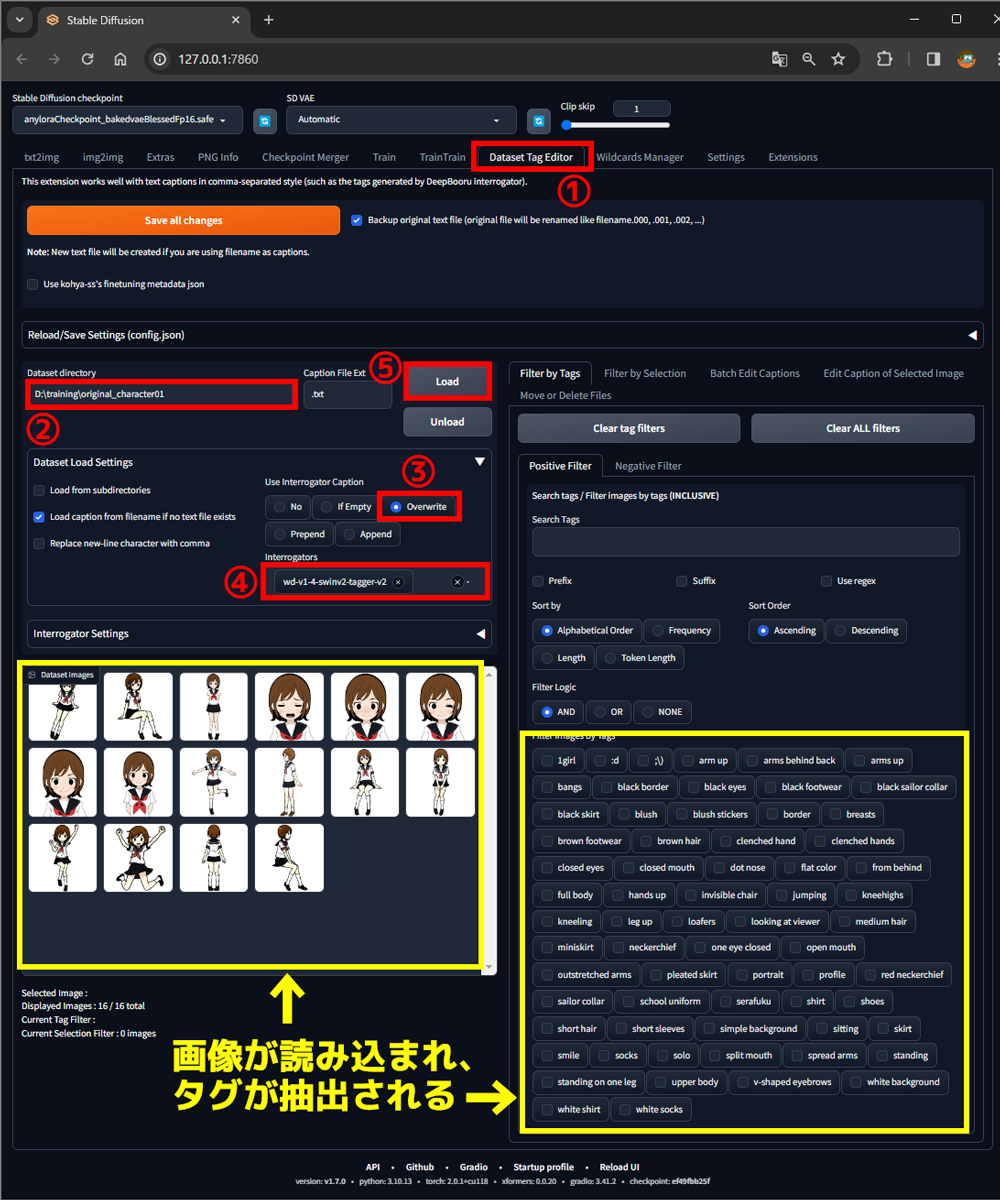
①Dataset Tag Editorタブを選択
②Dataset directory欄に先ほどコピーした画像フォルダのアドレスを貼り付け
③Use Interrogator CaptionをOverwriteに変更
④Interrogators欄で wd-v1-4-*** のいずれかを選択
⑤Loadボタンをクリック
Loadボタンを押すと画像と画像から抽出したタグが表示されます。(黄枠内)
6-3.学習させたいタグを選択して消去する
①Batch Edit Captionsタブを選択
②Removeタブを選択
③タグ一覧から学習させたいタグを選択
④Remove selected tagsボタンをクリック
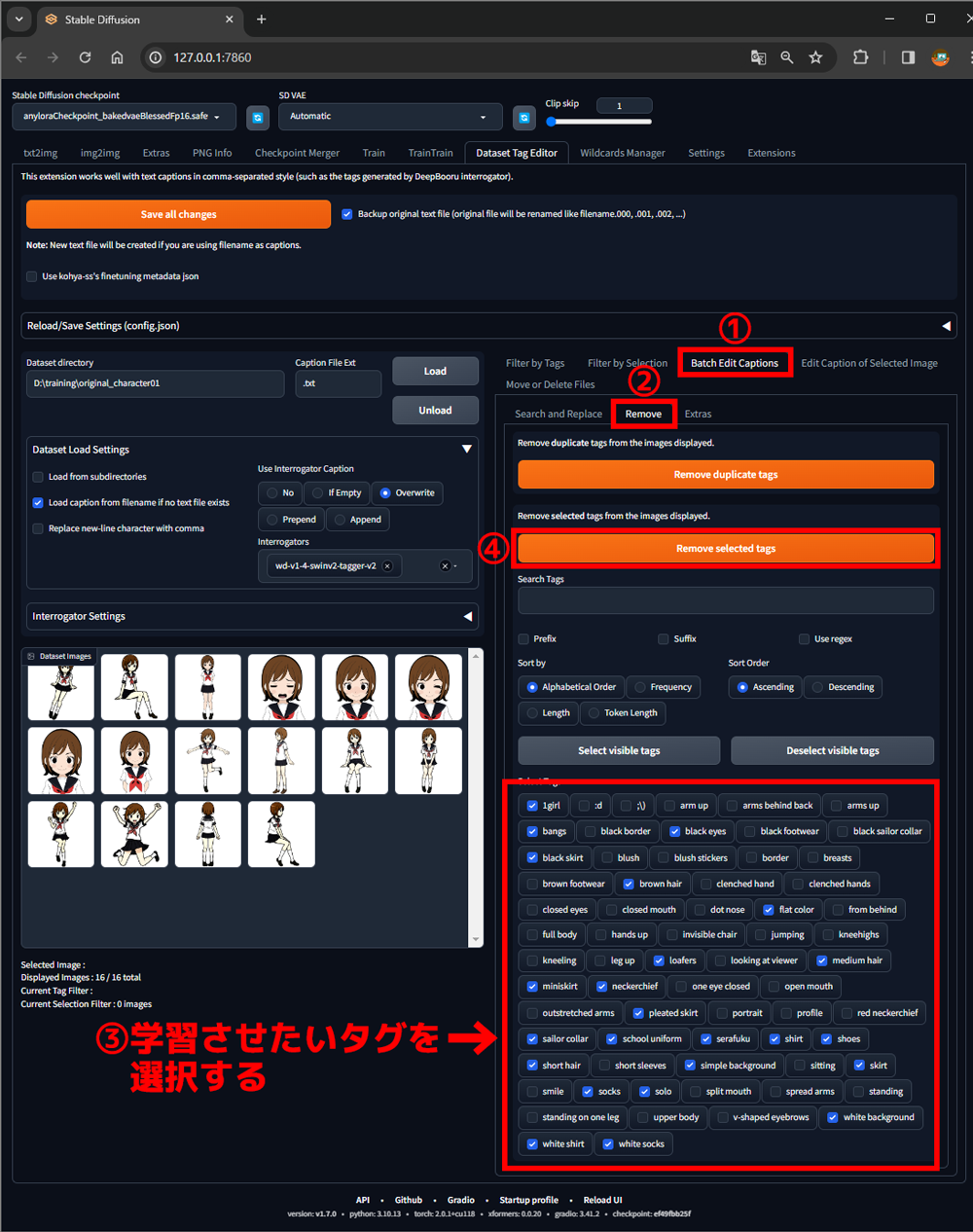
下のように選択したタグが一覧から消去されました。
タグの数が多い場合は、見落としがあるので③と④を繰り返して学習させたいタグを全て消去します。
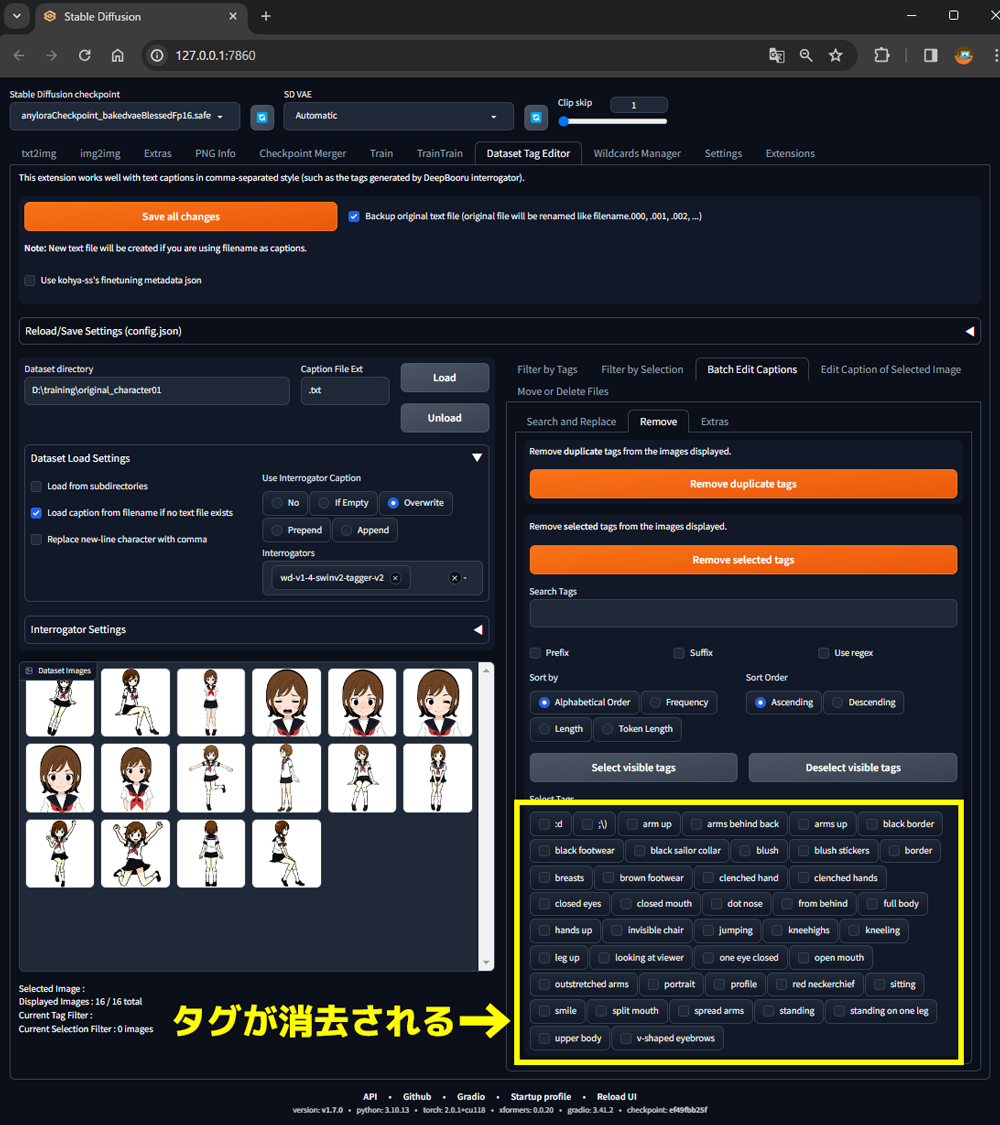
⑤Save all changesボタンをクリック
このボタンを押すとタグをテキストファイルとして書き出してくれます。
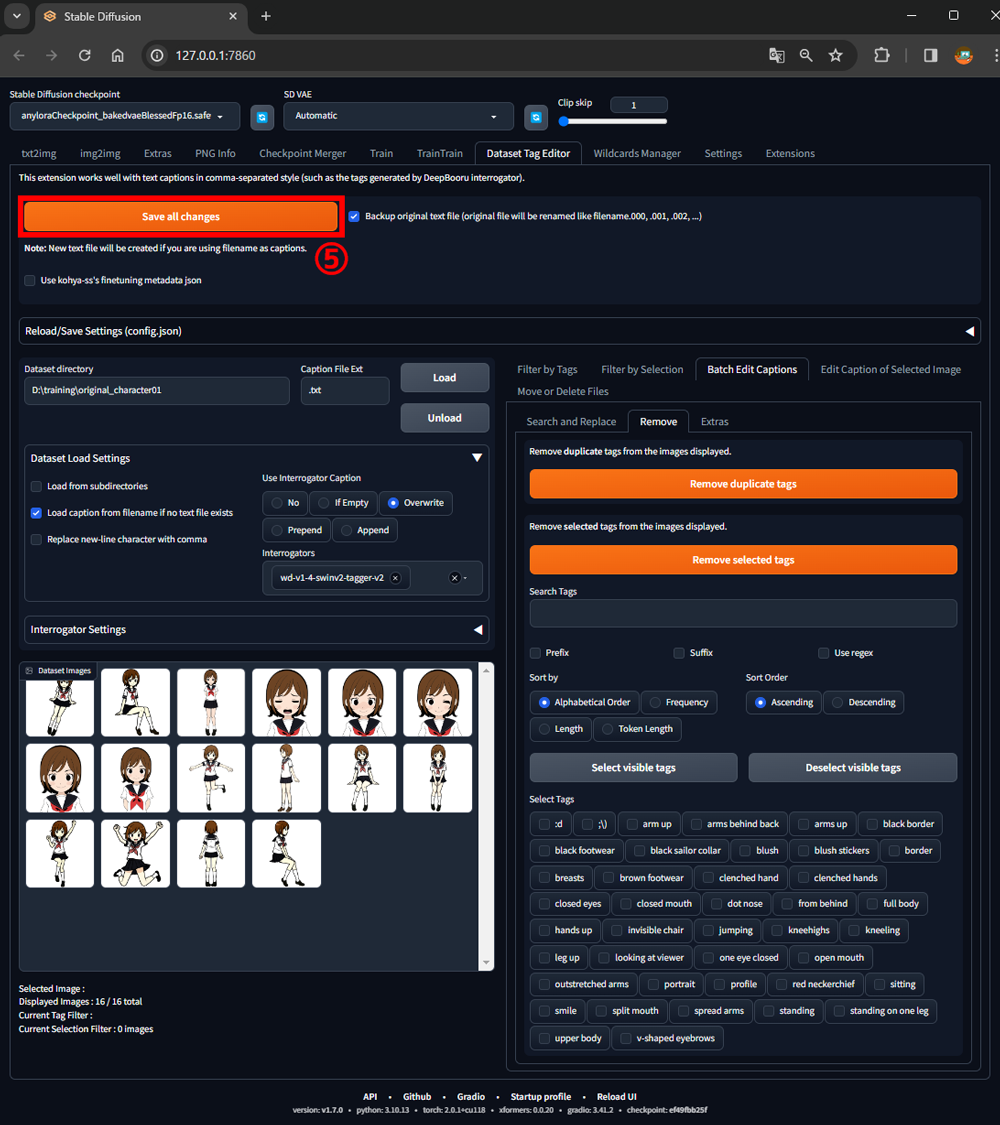
画像フォルダ内にテキストファイルが作成されました。
それぞれのテキストファイルには、学習させたいタグが消去されたプロンプトが記述されています。
これでLoRAを作る準備が整いました。
7.LoRAの作成(TrainTrainでの作業)
今回は、ほぼ標準設定のままでLoRAを作成してみます。
⓪画像フォルダの一つ上の階層のアドレスをコピー
この例では、D:¥training となります。
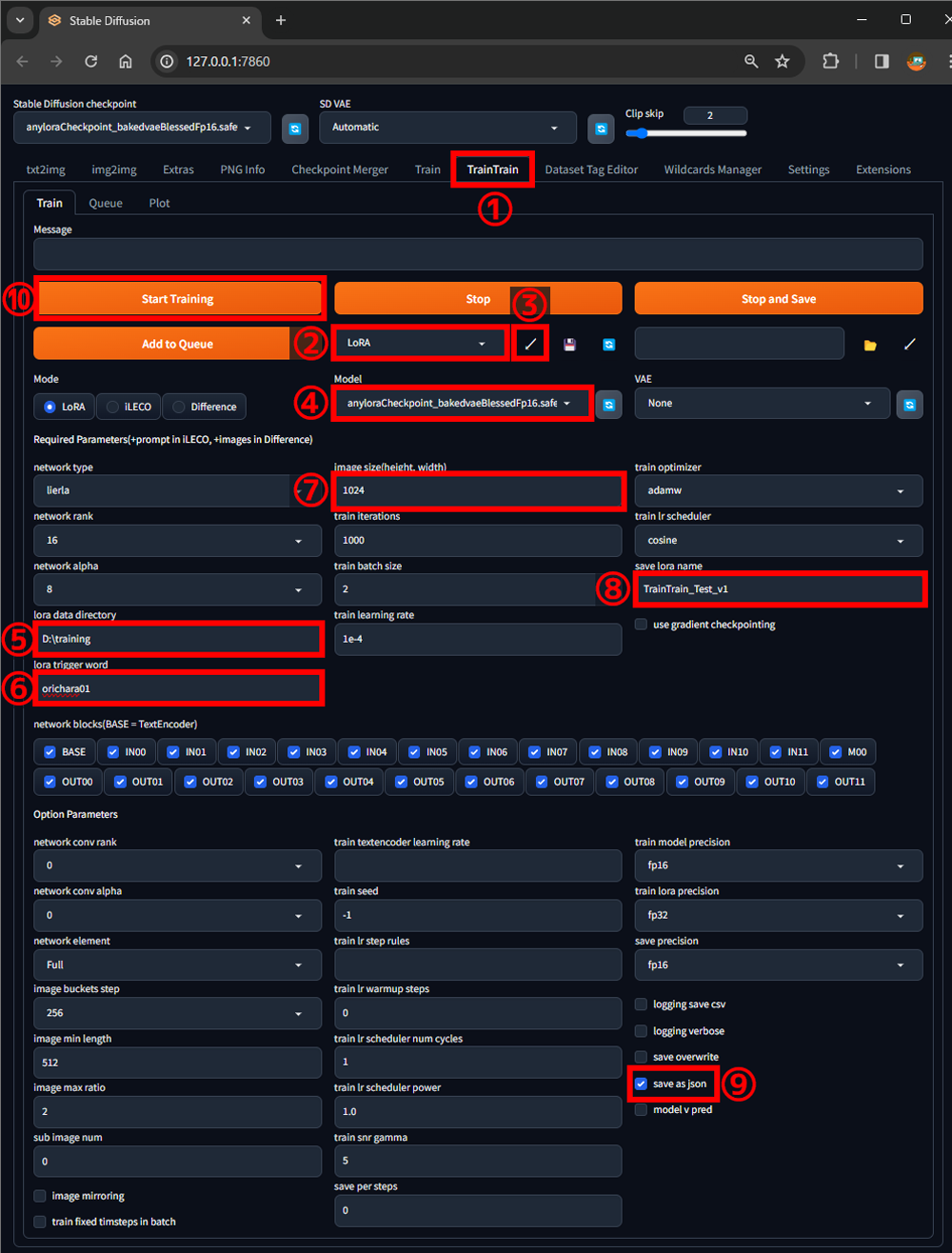
①TrainTrainタブを選択
②preset欄でLoRAを選択
③![]() アイコンをクリックしてLoRAプリセットを適用
アイコンをクリックしてLoRAプリセットを適用
④Model欄でModel(Checkpoint)を選択
この例では、LoRA作成に適していると評判の anyloraCheckpoint を使用します。
⑤上記⓪でコピーした画像フォルダの一つ上の階層のアドレスを貼り付け
⑥lora trigger word欄にトリガーワードを入力
LoRAを適用して画像生成する際、プロンプトに記述するトリガーワードを入力します。
ここでは、orichara01 というトリガーワードにしました。
※この例のようにトリガーワードに01、02のような連番を付けることは、お勧めしません。単に、orichara などにした方が良いでしょう。
⑦image size(height, width)欄に学習させる画像のサイズを入力
今回は、1024*1024 の画像を用意したので、1024 にします。
⑧save lora name欄にLoRAのファイル名を入力
この例では、TrainTrain_Test_v1 というファイル名にしました。
⑨save as jsonを選択(任意)
⓪~⑧で設定した内容を json というファイル形式で保存しておきます。
jsonファイルは、以下のフォルダに保存されます。
/stable-diffusion-webui/extensions/sd-webui-traintrain/jsons/日付フォルダ
次回以降は、各設定を保存したjsonファイルで読み込むことができます。
⑩Start Trainingボタンをクリック
Start Trainingボタンをクリックすると学習が始まります。
今回は、ほぼ標準設定のままLoRAを作成しました。主な項目と使用したグラフィックボード・メモリ容量について記載しておきます。
- 画像枚数:16枚
- 画像サイズ:1024*1024
- train iterations(反復回数):1000(標準値)
- train batch size:2(標準値)
- グラフィックボード:NVIDIA Geforce RTX4060Ti(16GB)
- メモリ:32GB
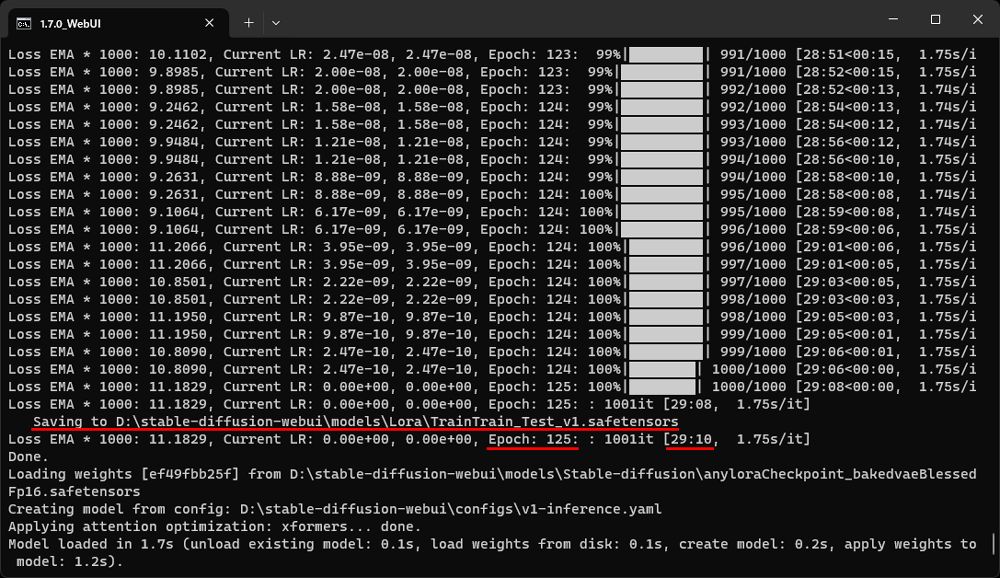
この設定と環境で学習にかかった時間は、29分10秒でした。
エポックは、125となっています。
kohya_ssなどを使用してLoRAを作成する場合は、以下の計算式で学習ステップ数を決める必要がありましたが、今回使用したTrainTrainでは、繰り返し数やエポックを指定する必要はなく、train iterations(反復回数)の値を指定するだけなので非常に簡単です。
画像枚数 × 繰り返し数 × エポック = 学習ステップ数
また、作成されたLoRAを所定のフォルダ /stable-diffusion-webui/models/Lora に自動保存してくれるので、ファイル移動などの手間が省けます。
8.検証
学習時間約30分で作成したLoRAは、いかがなものか?
早速、画像を生成してみましょう。
単純なプロンプトに作成したLoRA(TrainTrain_Test_v1)を強度1で適用して、20枚連続で生成して検証してみました。
容姿や服装に関しては、何も指示していません。
・プロンプト
orichara01, best quality, masterpiece, 1girl, smile, full body, standing, solo, white background, simple background, <lora:TrainTrain_Test_v1:1.0>,
・ネガティブプロンプト
EasyNegativeV2, painting by bad-artist-anime, bad-hands-5
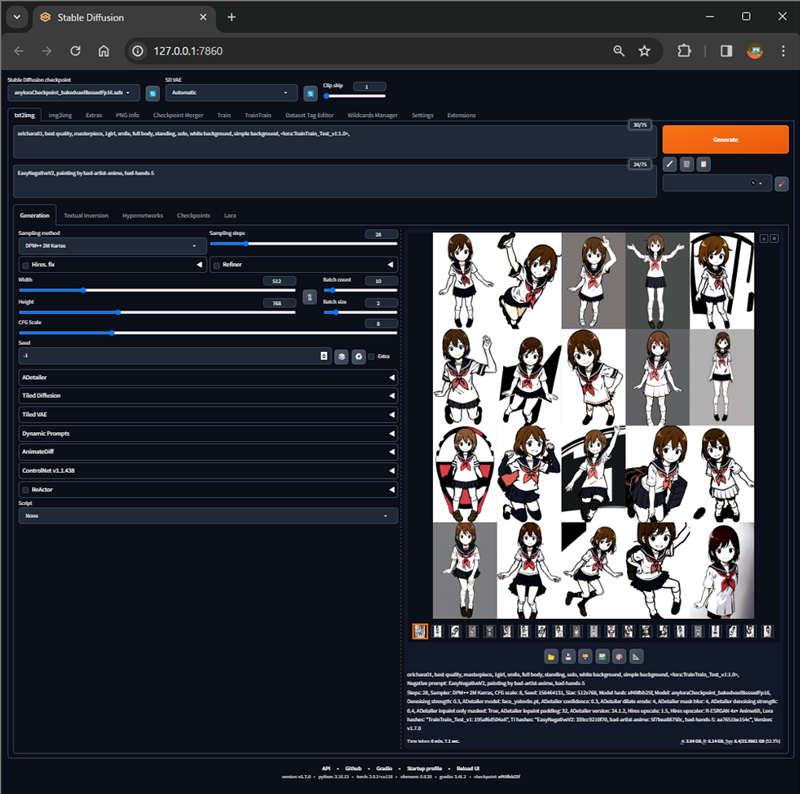
背景に余計な模様が出ているのと病的に色白な画像となっています。また、from above(上からのアングル)を強く学習している感じがします。
顔、髪型、服装などキャラクターに関しては、まずまずといった感じです。
ほぼ標準設定で作成したLoRAですが、しっかりと学習しています。
プロンプトを調整して生成すれば、もう少しマシな画像が生成できる可能性があります。
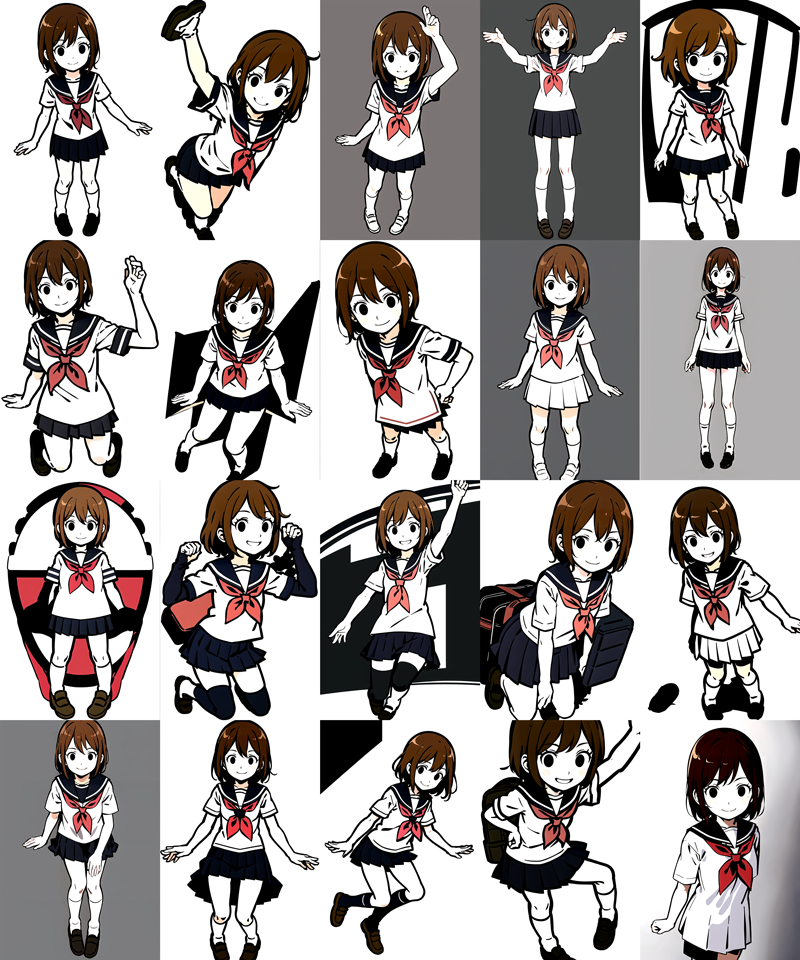
次にX/Y/Z plot(Prompt S/R)で強度0~1まで、0.2ずつ強くしながら生成して比較してみます。
強度0(一番左の画像)は、LoRAが適用されていない状態なのでAnyloracheckpointのキャラクターになっています。強度が上がるにつれて学習効果が表れていますが、それと同時に肌の色が抜けているのが分かります。
顔や服装、体型などに関しては満足のいく結果となりましたが、肌の色がダメですね。
確かに、学習画像を見返してみると肌の色が薄い感じは否めません。
学習画像の修正や差し替えが必要であることが判明しました。。。
画像の準備で手を抜くと、こういう結果となります。

下の画像は、学習画像の肌色を調整してから作成したLoRAの結果です。
LoRA作成時の各パラメータは、前回と全て同じにして作成しました。
肌色が改善されています。

9.まとめ
今回は、TrainTrainの細かな設定変更をせず、ほぼ標準設定のままでLoRAを作成しました。
標準設定のままでも、検証結果のように与えられた学習画像を忠実に学習してることがお分かりいただけたと思います。
TrainTrainでのLoRA作成は、外部ツールを使用せずWebUIで全て完結するので、他のツールに比べて分かりやすくて便利だと思います。また、設定項目がかなり精選されているので、他のLoRA作成ツールより扱いやすいと思います。
LoRA作りに興味をお持ちの方は、ぜひチャレンジしてみてください。
最後までお読みいただき、ありがとうございました。


コメント